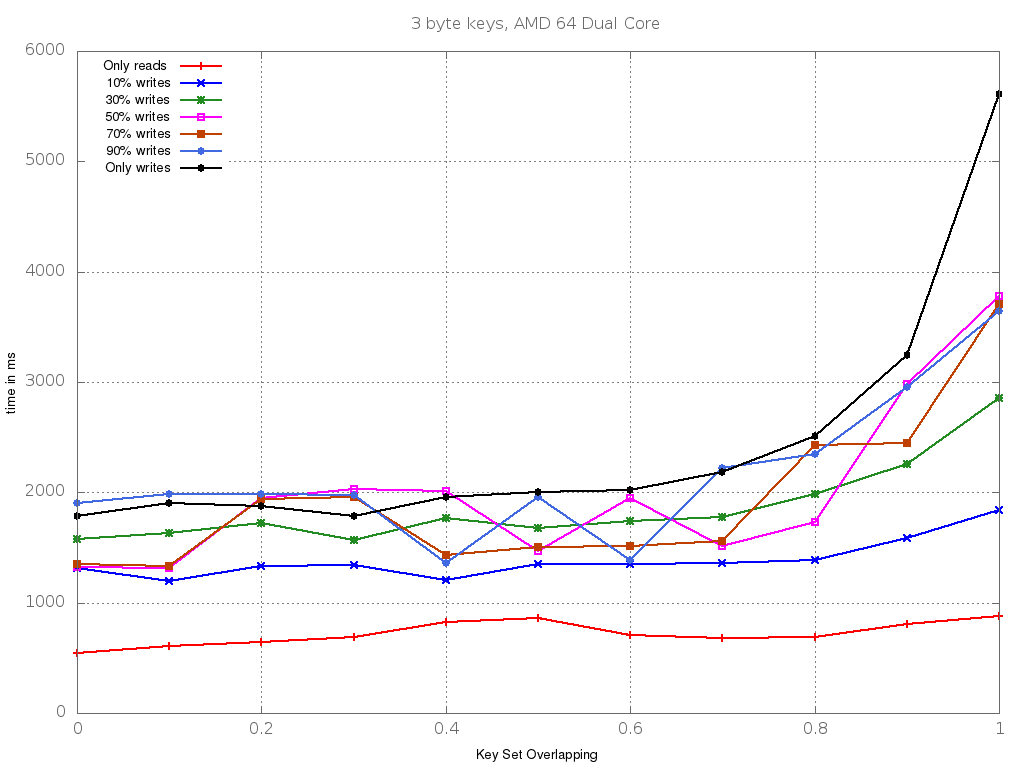
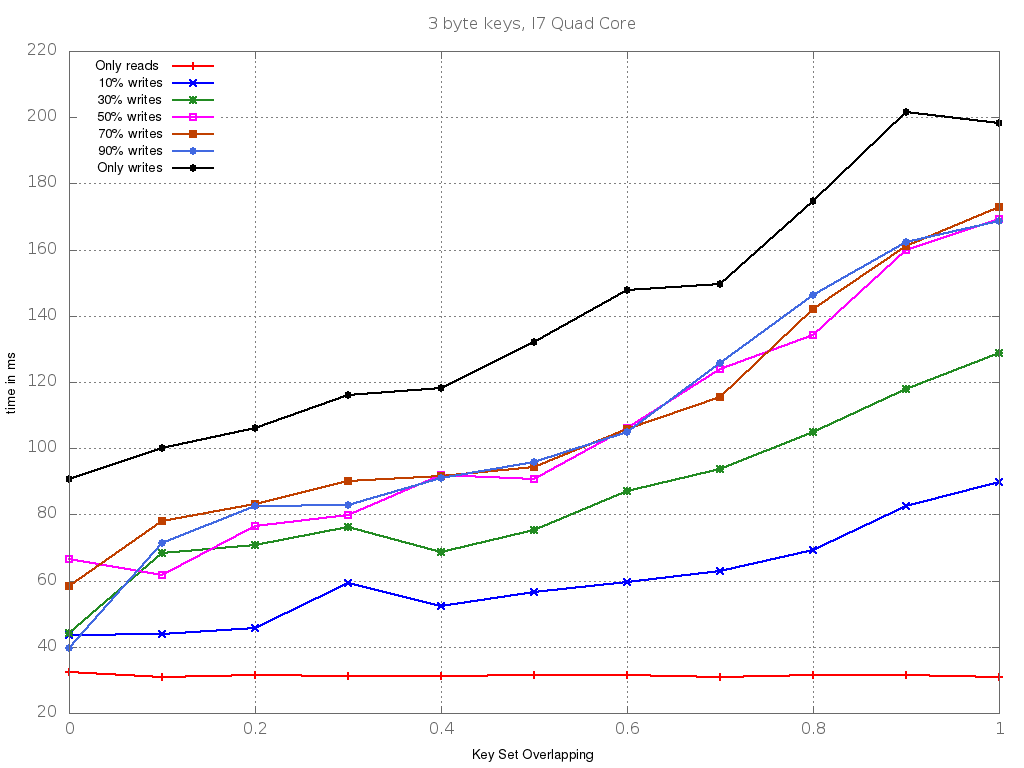
In Java, classes and class members have by default package visibility. To restrict or increase the visibility of classes and class members, the access modifiers private, protected, and public must be used.
| Modifier | Class | Package | Subclass | World |
|---|---|---|---|---|
public |
Y | Y | Y | Y |
protected |
Y | Y | Y | N |
| no modifier | Y | Y | N | N |
private |
Y | N | N | N |
(from Controlling Access to Members)
These modifiers control encapsulation along two dimensions: one dimension is the packaging dimension, the other is the subclassing dimension. With these modifiers, it becomes possible to encapsulate code in flexible ways. Sadly, the two dimensions interfere in nasty ways.
Shadowing
A subclass might not see all methods of its superclass, and can thus redeclare a method with an existing name. This is called shadowing or name masking. For instance, a class and its subclass can both declare a private method foo() without that overriding takes place. This situation is confusing and best to be avoided.
With package visibility, the situation gets worse. Let us consider the snippet below:
package a;
public class A {
int say() {return 1;};
}
package b;
public class B extends a.A {
int say() {return 2;};
}
package a;
class Test {
public static void main(String args[]) {
a.A a = new b.B();
System.out.println(a.say()); // prints 1, WTF!!
} }
(from A thousand years of productivity: the JRebel Story)
The second method B.say() does not override A.say() but shadows it. Consequently, the static type at the call site defines which method will be invoked.
One could argue that everything works as intended, and that it is clear that B.say() does not override A.say() since there is no @Override annotation.
This argument makes sense when private methods are shadowed. In that case, the developer knows about the implementation of the class and can figure this out. For methods with package visibility, the argument is not acceptable since developers shouldn’t have to rely on implementation details of a class, only its visible interface.
The static types in a program should not influence the run-time semantics. The program should work the same whether the variable “a” has static type “A” or “B”.
Reflection
With reflection, programmers have the ability to inspect and invoke methods in unanticipated ways. Reflections should honor the visibility rules and authorize only legitimate actions. Unfortunately, it’s hard to define what is legitimate or not. Let us consider the snippet below:
class Super {
@MyAnnotation
public void methodOfSuper() {
}
}
public class Sub extends Super {
}
Method m = Sub.class.getMethod("methodOfSuper");
m.getAnnotations(); // WTF, empty list
Clearly, the method methodOfSuper is publicly exposed by instances of the class Sub. It’s legitimate to be able to reflect upon it from another package. The class Super is however not publicly visible, and its annotations are thus ignored by the reflection machinery.
Package visibility is broken
Package-visibility is a form of visibility between private and protected: some classes have access to the member, but not all (only those in the same package). This visibility sounds appealing to bundle code in small packages, exposing the package API using the public access modifier, and letting classes within the package freely access each others. Unfortunately, as the examples above have shown, this strategy breaks in certain cases.
Accessiblitiy in Java is in a way too flexible. The combination of the fours modifiers with the possibility to inherit and “widen” the visibility of classes and class members can lead to obscure behaviors.
Simpler forms of accessibility should then be preferred. Smalltalk supports for instance inheritance, but without access modifiers; methods are always public and fields are always protected. Go, on the other hand, embraces package visibility, but got rid of inheritance. Simple solutions are easier to get right.
NOTES:
- In “Moderne Software-Architektur: Umsichtig planen, robust bauen mit Quasar” the author argues that method level visibility makes no sense. Instead, components consist of classes, which are either exposed to the outside (the component interface) of belond to the component’s internals and are hidden (the component implementation). This goes in the direction of OSGi and the future Java module system.