Assessing the scalability of programs and algorithms on multicore is critical. There is an important literature on locks and locking schemes, but the exact cost of volatile is less clear.
- Are volatile really free?
- Is volatile expensive?
- Java’s Atomic and volatile, under the hood on x86
- Cost of Volatile
For the software composition seminar, Stefan Nüsch and I decided to look at this topic. Essentially, we devised a benchmark where multiple threads would access objects within a pool. Each thread has a set of objects to work with. To generate contention, the sets could be fully disjointed, have partial overlap, of have a full overlap. The ratio of reads and writes per thread was also configurable.
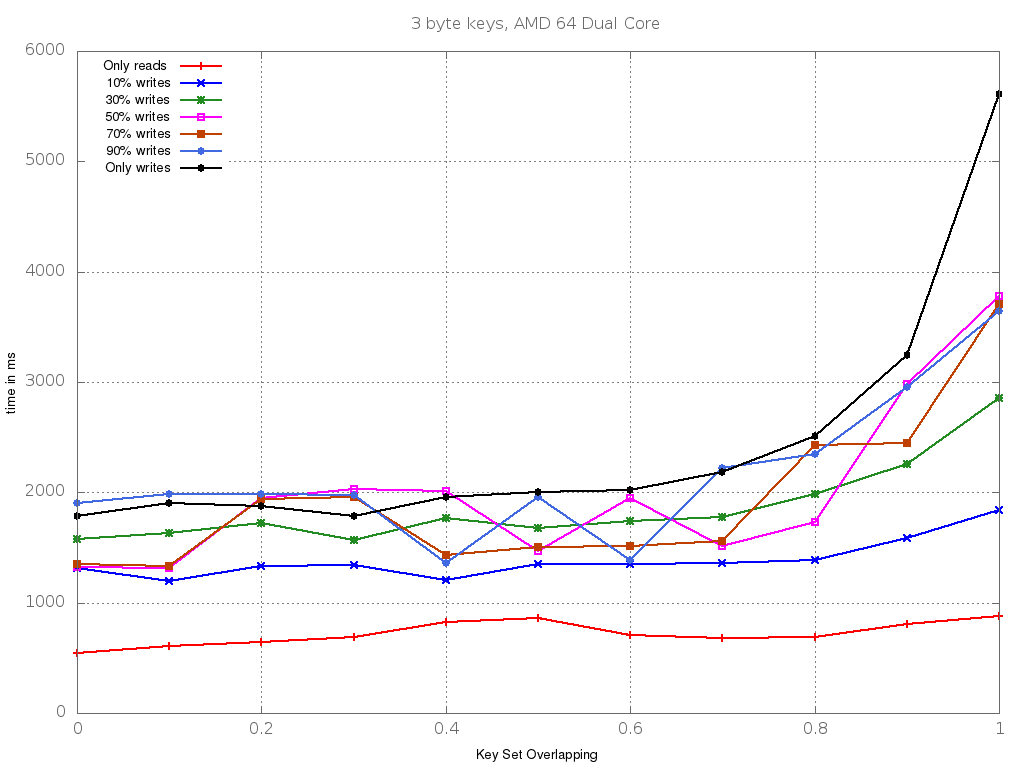
On an AMD 64 Dual Core, the graph looks as follows:
 On a i7 Quad Core, the graph looks as follows:
On a i7 Quad Core, the graph looks as follows:
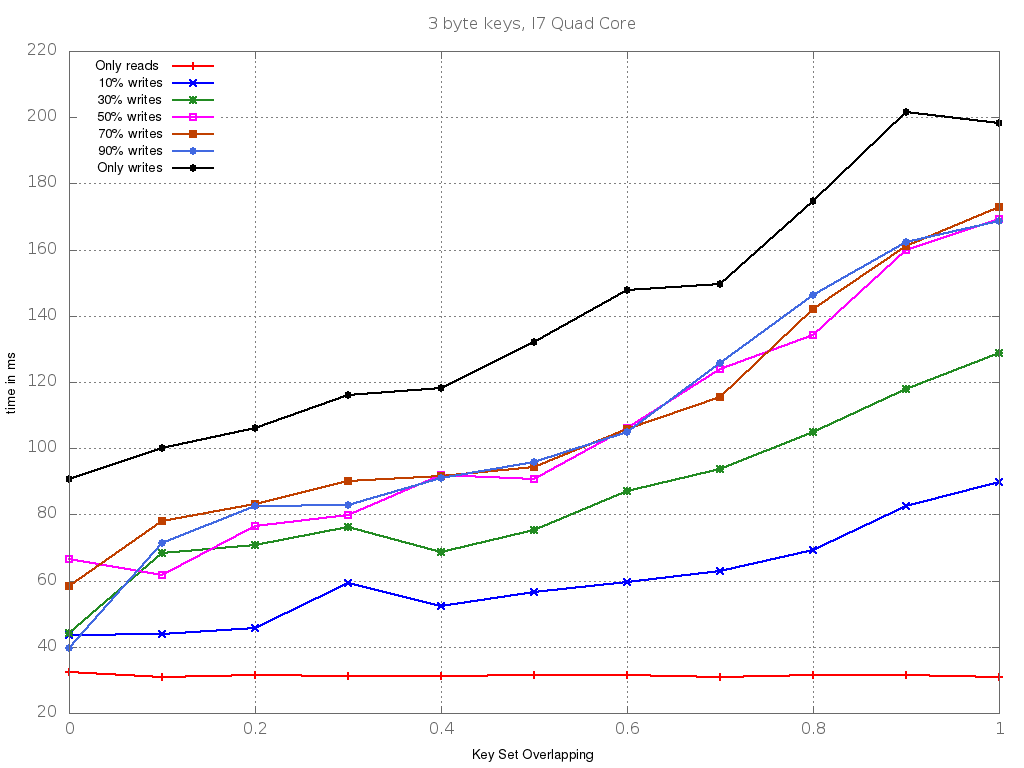 We clearly see that different architectures have different performance profiles.
We clearly see that different architectures have different performance profiles.
In future work, we could try to reproduce false sharing and assess the impact of other forms of data locality.
More details about the benchmark and methodology can be found in his presentation. The code in on github.
Here a some links about the semantics of volatile, and mememory management in general.
- Java Concurrency (&c): What Volatile Means in Java
- The Java Memory Model here, and the POPL’05 paper
- An Operational Semantics including “Volatile” for Safe Concurrency, JOT 09
- Double-checked locking is broken
- Thin locks: featherweight synchronization for Java, PLDI 98
- Memory Barriers: a Hardware View for Software Hackers
- What Every Programmer Should Know About Memory
- False Sharing
- Relaxed-Memory Concurrency
- The Silently Shifting Semicolon
