A large part of architecture relates nowadays to integration. Here’s list of good resources on API design:
Category: Architecture & Engineering
Putting the Software Architecture Metaphor to the Test
For a long time, I didn’t like the software architecture metaphor much. Software felt too malleable for such a static comparison. I preferred other analogies. But in recent years, I’ve come to appreciate it much more. The architecture metaphor actually works quite well.
Part of this realization stems from a better understanding of physical construction: how architects, civil engineers, electricians, plumbers, roofers, and interior designers collaborate.
Let’s make the parallel with a typical web project:
| Software Work | Construction Work | How Hard Is It To Change? |
|---|---|---|
| Choosing the stack (e.g., Angular, Spring Boot) | Choosing materials (Concrete, wood, building fabric) | Foundation. Changing this may mean rewriting the whole system. |
| Decomposition (Domains, key cross-cutting concepts) | Structural layout (Load-bearing walls, space for conduits, navigation) | Support Structures. Changing it requires major effort; it shapes the system. |
| Defining constructs (Key entities, services, etc.) | Systems selection (Kitchen, flooring, non-load-bearing walls, plumbing, elevators) | Substantial Effort. Can be modified, but it is messy and disruptive. |
| Detailed design and implementation | Interior design | Easy. Like repainting a room or swapping furniture. |
The upper items are harder to change than the lower ones1.
Detailed design and implementation is easy to change, like interior design. If a button is in the wrong place or a form field is confusing, you can fix it in an afternoon. It’s like deciding to paint the living room blue instead of beige, or replacing the carpet with hardwood. The structure remains untouched, and the work is contained.
Key constructs in the project, like the domain model, can be modified with substantial effort. Imagine you need to move the main water heater, remove a non-bearing wall, or reroute the electrical panel because the building codes changed or your needs evolved. You can’t just paint over it; you have to shut down power, drain pipes, and carefully navigate around existing walls. In software, this is like changing how a “User” entity relates to an “Order” or splitting a service into two. It breaks existing integrations, requires data migration, and forces the whole team to pause while the “plumbing” is reworked.
How the software is decomposed is even harder to change. The decomposition shapes the system and changing it requires major effort. You are changing key support structures. Think of it as realizing halfway through construction that the staircase is in the wrong place, blocking the flow of the entire house. To fix it, you might have to tear down a load-bearing wall, install temporary supports, and rebuild the second floor. In software, this is the nightmare of trying to move from a monolith to microservices, or redefining your core business boundaries after years of development. It’s not just a refactor; it’s a reconstruction of how the teams and systems communicate. Extensions are far easier, like a new business module for software or a veranda for a house.2
Finally, the technologies that are used lay the foundation. Changing them may mean rewriting the whole system. This is the equivalent of deciding three years into a build that you want to switch from a concrete foundation to a timber frame. You can’t just patch it; you have to dig up the site and start from zero. In software, this is the decision to migrate from Java to Go, or from SQL to NoSQL. It often means the old system becomes obsolete, and the only path forward is a complete rewrite.3
I disliked the architecture metaphor because I had categorized too much work under it. Over the lifetime of a software system, architecture happens intensely at the beginning and then occasionally later on. Most of the work isn’t architecture work. It’s interior design and systems selection. People move in and out, swap furniture, and do light renovations. It requires taste and care and is valuable—but it isn’t architecture.
- This is similar to concept of “shearing layers” from Duffy and Brand. The layers in the table are a variation of their concept. ↩︎
- Over long period of time, buildings can still change significantly, as shown in the book “How Buildings Learn” from Brand. ↩︎
- Some pretty impressive can happen to buildings nevertheless, like rotating a building 90°! ↩︎
AI and the Economics of Software Development
In his seminal essay “No Silver Bullet,” Brooks defined the concept of accidental versus essential complexity in software development. Essential complexity is the irreducible complexity of the problem you want to solve. Accidental complexity is the complexity introduced by implementation choices, which we aim to minimize.
Typing was never the bottleneck in software development, but managing accidental complexity is. There are good reasons to think AI can effectively address accidental complexity significantly.
However, to understand where AI can make the greatest impact, we must first examine where this accidental complexity originates. A major contributor is that, by default, we engineer systems using technologies designed for internet-scale applications. If your software is internet-scale, the complexity of modern frameworks is partly essential—scaling brings irreducible complexity with it. But if your system isn’t internet-scale, all this complexity is accidental. Instead of a simple PHP file, you now have an Angular application with a separate frontend and backend in a three-tiered architecture consisting of at least 20 files. You are expected to build your application cloud-native, even if you don’t really need the cloud.
There are many straightforward refactorings that teams don’t implement because they are too expensive. Think of changing the name of a domain attribute in your model. It can easily ripple through many artifacts—from domain models to unit tests to database schemas. Basically, many cross-cutting changes are usually not carried out because they have poor economics. Over time, the consequence is design erosion.
AI excels at these changes, executing ripple effects across the codebase without the cost or fatigue that currently deter human developers. More broadly, anything that qualifies as “boilerplate code” is accidental complexity and can be handled by AI. This significantly changes the economics of software maintenance and development.
Related
- This post has been inspired by https://ian-cooper.writeas.com/is-ai-a-silver-bullet
- https://haskellforall.com/2026/03/a-sufficiently-detailed-spec-is-code – I think the argument here is missing the distinction between essential and accidental complexity
Will AI Kill Agile Software Development?
Will AI kill agile software development? Looking at Atlassian’s recent plunge suggests investors think the usual agile setup—JIRA, stories, sprint boards—could face a big disruption. That makes many wonder if the old way of working with stories and features will disappear.
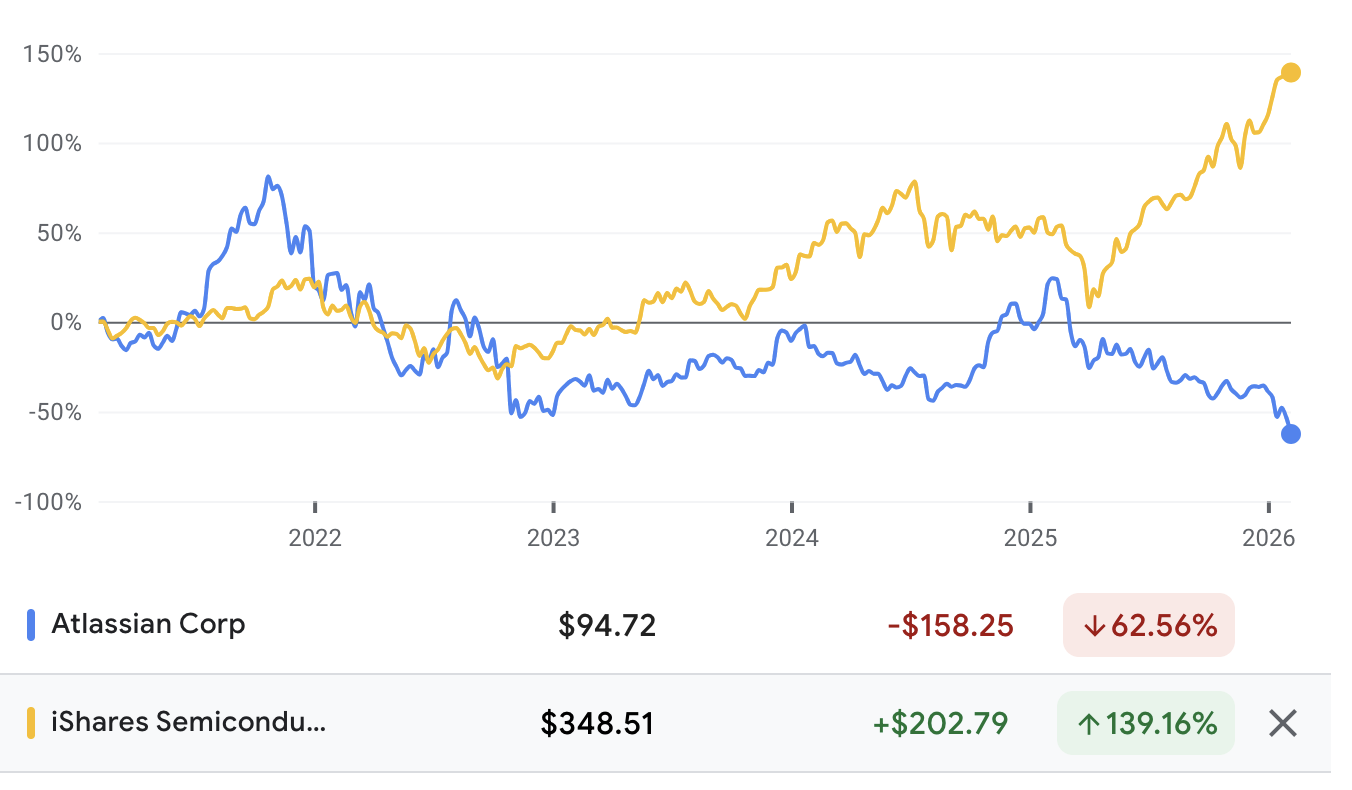
At its core, agile is about evolving requirements iteratively. Stories and features aren’t the real requirements, they’re just a way for people to organise work. Even if machines write the code, we still need a clear set of goals. Those goals will still exist, but they might live somewhere else.
One option is to keep requirements inside the codebase itself, either as additional artifact or in the form of tests. Big or regulated projects will still need dedicated requirement‑management tools (for example, Polarion) to keep versions, approvals and audit trails. Those tools will keep feeding AI the context it needs while providing the governance many companies require.
AI can actually help the agile process. A product owner can give a high‑level feature description to an AI, and the AI can break it into small implementation steps (stories), write acceptance criteria and draft a first version of the code. The backlog stays, but the heavy lifting of splitting work is done by the machine, possibly asking for clarification interactively.
Whether the implementation steps will be persisted if the AI does the work and not a human will depend on our needs of observability. Since it doesn’t cost much to persist the implementation steps, I guess we will keep storing them to track progress and flag problems.
The three main parts of software delivery—requirement management, work organisation and development environments—will still be separate, but AI will tie them together more tightly. Requirement‑management platforms will keep governance, work‑organisation tools will continue to help teams prioritise and visualise work, and IDEs such as IntelliJ will still provide debugging, testing and refactoring, now with extra AI‑generated code suggestions.
Overall, AI is unlikely to kill agile — at least not yet. Instead, it will change where requirements live, how stories are created and how tools interact with each other.
TOGAF: The Good Parts
TOGAF is a framework for enterprise architecture management. Enterprise architecture aims at aligning the business and IT to achieve the strategic goals of the enterprise. Enterprise architecture supports digital transformation in large enterprises.
The core of the TOGAF framework is the architecture development method (ADM).
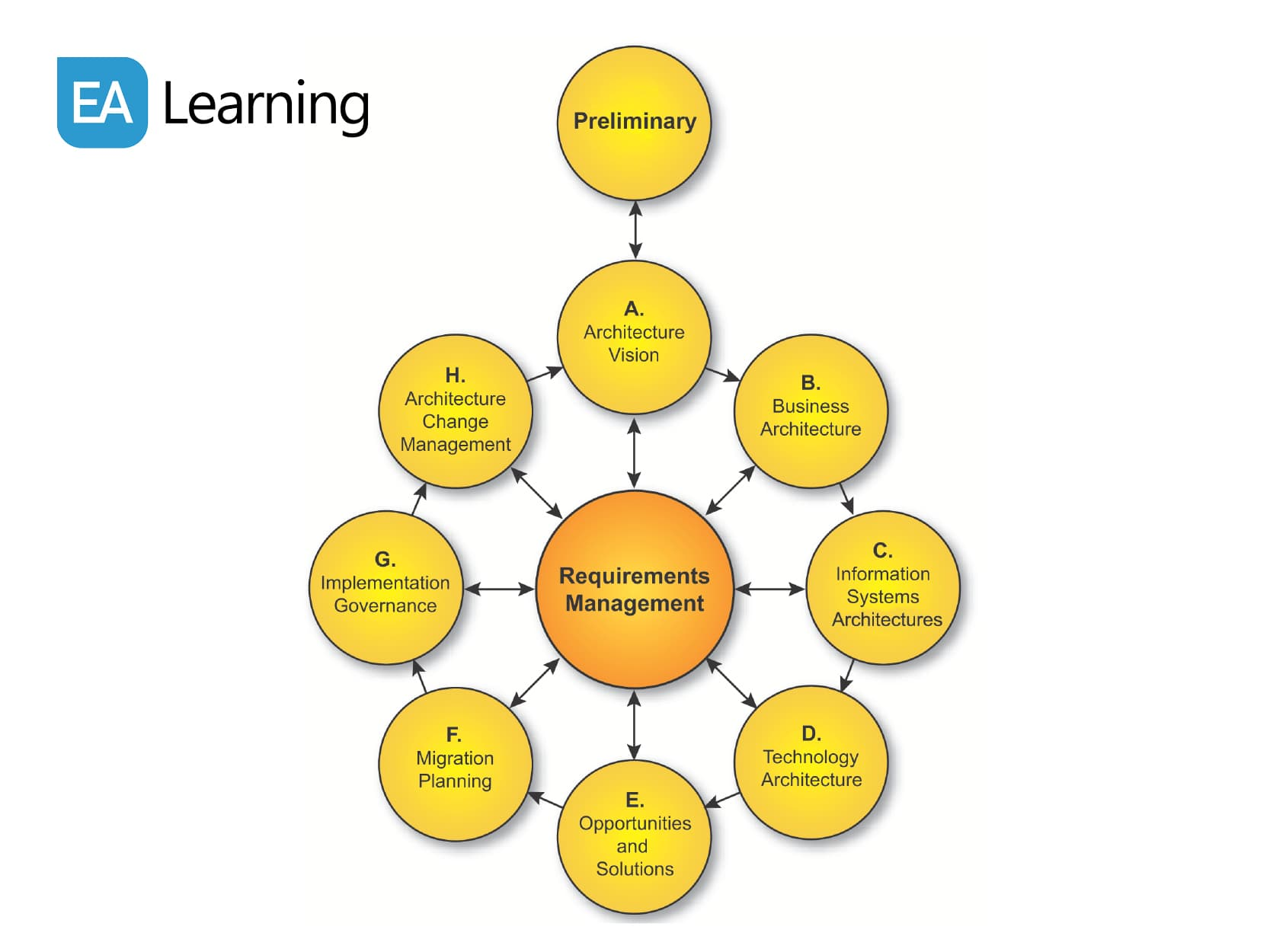
In a nutshell, the method works as follows:
- in the preliminary phase, you build up the enterprise architecture capability itself (that is, you establish and tailor the TOGAF framework)
- the architecture work is triggered by architecture changes that go through the whole cycle.
- Phase A-D work out the candidate architecture, which is decomposed in four architecture domains: business, application, data, and technology. Application and data architecture are grouped together into “information systems architecture” in the cycle.
- The candidate architecture is solution-neutral. Up to this point, you identify changes to business processes, applications, interfaces, data models, platforms without defining a concrete implementation.
- A more concrete solution is worked out in phases E and F. The selection of precise technologies, implementation architecture styles (microservices, streaming, etc.), or vendors come especially in these phases.
- Phases E and F also cover planning with key stakeholders using an architecture roadmap and migration plan that define the work packages.
- In phase G, the project is handed over to the implementation organization (e.g. an agile release train). Expectations about the outcome to deliver and quality are agreed in an “architecture contract” between the architecture and the implementation organization.
- Phase H is a retrospective where improvements are formulated and kickstart a new cycle.
The cardinal sin to avoid is to jump from A to G, namely, from the business need to the implementation plan. We’ve all been there: the business has an idea and mandates a team to realize it, without looking left or right and how it would fit in the bigger context. This usually leads to specific solutions for specific problems. Over time, the architecture landscape becomes fragmented and inconsistent. The goal of enterprise architecture is precisely to avoid this. Business needs should be supported by a consistent architecture strategy.
This goal of consistency is supported in TOGAF with the concept of building blocks. The architecture consists of architecture building blocks (business, application, data, or technology) that can be used or reused. In phase B/C/D architects identify which building blocks have to modified, added, or removed for a given change. This is the gap analysis between the baseline and target architecture. In phases E and F, when the concrete solution architecture is worked out, solution architects identify solution building blocks to fulfill the requirements.
Part of TOGAF is also a content metamodel that define key entites to model the four architecture domains (business, application, data, or technology). It’s pretty generic but can be good starting point. You will probably have to refine it though, so that it becomes really useful (e.g. refine the technology metamodel to distinguish between plattform and frameworks).
These core concepts of TOGAF define a useful methodology to tackled complex architecture change. It’s the good parts.
From the perspective of agility, the framework is neither good nor bad. It will all depend on your implementation.
The framework is iterative in nature. Each architecture change goes through the cycle and is an iteration. How big the changes are, how long the cycles last, and how many iterations can run in parallel will depend on your implementation. Part of the preliminary phase is the idea to tailor the framework to your needs. You can implement the core idea in a bureaucratic manner with many deliverables and approvals. But you can also implement the core ideas in a lightweight manner with a few well chosen checkpoints. Similarly, you can partition the enterprise architecture work in “segments”. What they are and how big they are will depend on your implementation.
The bad parts of the framework are the useless ornaments around the core concepts. I can make a list:
- The many deliverables expected to be produced along the cycle. I like the core concepts as long as they remain concepts. But TOGAF also defines a set of deliverables that probably are never implemented as such.
- The template library documents predefined viewpoints that can be use to document the architecture. This level of details is mostly useless.
- The content metamodel comes with two additional references architectures to model the technology and application domains. This complexifies the discussion about modelling without bring much benefits.
- The framework comes with a set of techniques that can be employed to carry out the phases. What has been defined as technique or not seem rather arbitrary. The techniques can serve as inspiration to conduct real work, but I doubt they will be followed as such.
- The framework defines a classification scheme for building blocks, ranging from generic to enterprise-specific, called the enterprise continuum. The value of the continuum as concept and its applicability are rather unclear.
These ornaments make the framework bigger with details, without being practical enough to be really useful. They mostly distract rather than help.
Talk: Software Architecture in Pratice (@Unibe)
I was invited by Prof. Oscar Nierstrasz (my PhD advisor) to give a guest lecture a the university of Bern on the topic “Software Architecture in Practice”.
What Makes a Good Microservice?
The microservice architectural style is almost a decade old!
The term was widely popularized with the article “microservices” from Fowler in 2014. It emerged as a consequence of cloud platform and using the cloud as a distributed operating system.
Many companies abandoned monolith around this time and paved the way towards microservice: Amazon, Netflix, Spotify, etc. Here’s a serie from Airbnb: Building Services at Airbnb
Over the next years (or decade), the industry learned the pitfalls of microservices, when the style makes senses and when it’s overengineered. Ultimately, it’s about balancing complexity.
There are cases when you don’t need microservices. DHH’s “majestic monolith” is valid counter-argument.
Ultimately, the question shouldn’t be “What makes a good microservice?”, but “What makes a good microservices architecture?” Microservices, per definition, don’t come alone.
A Comparison of Mobile Messaging Architectures
A project I’m working on involves changing the messaging technology for the delivery of realtime information to train drivers using iPad. This project made me interested in the various ways to design realtime messaging plattforms for mobile clients.
Unlike realtime messaging systems for web or desktop applications, mobile applications have to deal with the additional concern of unreliable connectivity. This unreliable connectivity is more subtle than I though. Here are for instance a few points to consider
- no connectivity or poor connectivity (tunnel, etc.)
- the device my switch from 5G to WLAN
- connection breaks when app goes in the background
- Different WLAN HotSpots (Androis, iOS) result in different behavior
You need to design your application to support these use cases correctly.
Here are some aspects of the communication that you need to consider
- Does the client need to load some state upon connection?
- Have updates a TTL?
- Are messages broadcasted to several clients or unique for the clients?
- Is message loss important or not?
- Does the server need to know which clients are connected?
- Do you have firewall between client and server?
Depending on the answers to these questions, you migth decide to establish a point-to-point onnection from the device to the backend. If you want to broadcast information to several clients you need to do this yourself in this case. You will also need to manage the sate in the backend yourself. Tracking the presence of the client is trivial, since there is one connection per client. Several technologies exist for this use case:
- Server-Side Event
- HTTP Long Polling
- gRCP
- WebSocket
You might otherwise decide to rely on a messaging system with publish-subscribe. The most common protocol for mobile messaging in this case is MQTT, but there are others. With a message broker, the broker takes care to broadcast message and persist the state according to the TTL. Tracking the presence of the client can be achieve with MQTT by sending a message upon connection and using MQTT’s “Last Will Testament” upon connection loss.
There are of course more details to take care when comparing both approaches, especially around state management. For instance, how to make sure that outdated messages are ignored.
We chose the latter option (MQTT) for our project, but I’m sure we could have achieved our goal with another architecture, too.
MORE
Apprently Uber and LinkedIn rely on SSE:
Beyond Events: the Stream Abstraction
In an event-driven system, the unit of abstraction is the event. An event is a notification about something happening in the system. Events can be processed and lead to other other events.
In systems relying on streams, the unit of abstraction is the stream. A stream is a sequence of events, finite but also possibly infinite. Rather than processing individual events, you manipulate streams.
If you simply want to react to each event, the difference is insignificant. For more complex situations, using streams makes it easier to express the processing. Streams are manipulated with various operators, like map, flatMap, join, etc. Implementing windowing is for instance a trivial task with streams – just use the right operator – whereas it would be a complicated task using only events.
One main use case for streams is to implement data pipelines. In this case we speak of stream processing. This is what Apache Flink and Kafka Streams are for. Stream processing is typically distributed on several machines to processe large quantities of data. The processing must be fault-tolerant and accomodate the failures of individual processors. This means that such technologies have sophisticated approches to state management. In the case of Kafka Stream, part of the heavy lifting is delegated to Kafka itself. Durable logs enable the system to resume after a failure, if needed reprocessing some data a second time.
Streams can also be used within applications to locally process data. This is what RxJava and Akka Streams are for. This tend to be referred as reactive programming and reactive streams. You use reactive programming to process asynchronous data, for instance video frames that need to be buffered. Rather than using promises or async/await to handle concurrency, you use streams.
There are many similarities between stream processing and reactive programming but also differences. In both cases, we find sources, streams, and sinks for events. In both case, you have issues with flow control. That is, making sure the producers and consumers can work at different paces. Since both use cases differ, the abstractions might differ, though. Streams in reactive programming supports for instance some form or exception handling, similar to regular java exceptions. Exception handling in stream processing is different. With reactive programming, buffering will be in-memory. With stream processing, buffering can be on disk (e.g. using a distributed log).
The stream, as an abstraction, is a relatively young one. It isn’t as well established as, say, relational databases. The terminology varies across products as well as concepts. The difference between stream processing and reactive programming is also not fully understood. For some scenario, the differences are irrelevant. As evidence that the field matures, some efforts to standardize the concepts have already started. The new java.util.Flow package is a standard API for sources (called publisher), streams (called subscription), sinks (called subscriber) in reactive programming. Alone, it doesn’t come with any standardized operator, though. This makes its usefullness at the moment limited to me. Project Reactor‘s aim is similar and it’s an implementation of the reactive streams specification that is embeddable is various framework, e.g. spring. Its integration in spring cloud stream effectively bridges the gap between reactive programming and stream processing.
The stream, as an abstraction, is very simple but very powerful. Precisely because of this, I believes it has the potential to become a core abstraction in computer science. It takes a bit of practice to think in terms of streams, and once you get it, you see possible applications of streams everywhere. So let’s stream everything!
More
- Event-driven system
- Stream processing
- https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102
- https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
- https://www.lightbend.com/blog/cloud-native-streaming-data-with-spark-flink
- https://www.lightbend.com/blog/cloud-native-streaming-data-with-akka-streams-kafka-steams
- https://www.lightbend.com/ebooks/fast-data-architectures-for-streaming-applications-oreilly-2nd-edition?utm_source=lbnd
- https://beam.apache.org/
- Reactive programming
- Distributed log
- Event Sourcing
When You Should Rewrite
When the architecture of a system starts to show its limits, it’s tempting to throw everything away and start from scratch. But a rewrite has challenges too. The existing software is a value-generating asset and must be maintained. The new architecture is unproven and comes with risks. Reaching feature parity can take years, and the rewrite turns also into an integration challenge to inteface the old and the new system. If a big bang approach is chosen, planing the switchover without data loss becomes a project on its own. These are just a few of the considerations, far from an exhaustive list.
Joel Spolsky wrote in 2000 an influential article discouraging rewrites, calling a rewrite the “single worst strategic mistake” you can make. Many developpers know this article and it often cited. Developpers are generally wary of rewrites. I love this description from Tyler Treat:
“Rewrite” is a Siren calling developers to shipwreck. It’s tempting but almost never a good idea
Yet, many software systems are regularly rewritten, as seen by the numerous articles listed below. And many rewrites are successful.
Whether you should rewrite your project or not can only be answered by yourself (or your team). Too many factors impact such a decision to be turned into a decision algorithm. Often, to rewrite or not ist not a binary decision anyway. There are nuances, for instance, which components of the system to rewrite. How much of the old system do you need to replace to call it a rewrite?
Having been working on Smalltalk for some years, I can confirm you that you can go a long way without a rewrite. Indeed, the Smalltak images that we use today are in fact “ancestors” of the very images of the 80s. All changes have been pushed within the environment itself, without a rewrite, even without a restart (because the concept doesn’t exist in Smalltalk).
I expect to hear about a few more software rewrites in my career, because it’s inherently tied to software evolution. A software rewrite might have a negative connotations sometimes, for instance when it’s driven because of massive technical debt. But most software rewrites are driven by increasing requirements. You rewrite your system because you are asked to make it work beyond what it was intially intended for. Actually, it’s the price you pay if your system is too successfull.
MORE
Some stories about rewrites or significant rearchitecturing work that I liked:
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum
- Hazards And Safeguards for Software Rewrites – Industrial Logic
- Things You Should Never Do, Part I – Joel on Software
- Second System Effect
- The Big Rewrite – Chad Fowler
- https://medium.com/@terrycrowley/arrival-of-the-fittest-be3b8db0d8bf#.7r2yigf6w
- https://drewdevault.com/2018/05/27/Why-rewrite-wlc.html
- https://eng.uber.com/rewrite-uber-carbon-app/amp/
- https://martinfowler.com/articles/break-monolith-into-microservices.html
- https://ckeditor.com/blog/Lessons-learned-from-creating-a-rich-text-editor-with-real-time-collaboration/
- https://signalvnoise.com/posts/3856-the-big-rewrite-revisited
- https://engineering.linkedin.com/blog/2018/12/coding-conversations–interviews-on-replacing-infrastructure-sys
- https://changelog.com/posts/the-many-reasons-replatforming-freshbooks-should-have-failed-and-why-it-succeeded
- https://mobile.twitter.com/johnsundell/status/1018101018805096450?s=20
- https://increment.com/frontend/making-vue-3/
- http://www.bennorthrop.com/rewrite-or-refactor-book/chapter-2-the-risks-of-rewrites.php
- https://slack.engineering/how-big-technical-changes-happen-at-slack/
- https://mobile.twitter.com/StanTwinB/status/1336890442768547845
