A large part of architecture relates nowadays to integration. Here’s list of good resources on API design:
Author: ewernli
Putting the Software Architecture Metaphor to the Test
For a long time, I didn’t like the software architecture metaphor much. Software felt too malleable for such a static comparison. I preferred other analogies. But in recent years, I’ve come to appreciate it much more. The architecture metaphor actually works quite well.
Part of this realization stems from a better understanding of physical construction: how architects, civil engineers, electricians, plumbers, roofers, and interior designers collaborate.
Let’s make the parallel with a typical web project:
| Software Work | Construction Work | How Hard Is It To Change? |
|---|---|---|
| Choosing the stack (e.g., Angular, Spring Boot) | Choosing materials (Concrete, wood, building fabric) | Foundation. Changing this may mean rewriting the whole system. |
| Decomposition (Domains, key cross-cutting concepts) | Structural layout (Load-bearing walls, space for conduits, navigation) | Support Structures. Changing it requires major effort; it shapes the system. |
| Defining constructs (Key entities, services, etc.) | Systems selection (Kitchen, flooring, non-load-bearing walls, plumbing, elevators) | Substantial Effort. Can be modified, but it is messy and disruptive. |
| Detailed design and implementation | Interior design | Easy. Like repainting a room or swapping furniture. |
The upper items are harder to change than the lower ones1.
Detailed design and implementation is easy to change, like interior design. If a button is in the wrong place or a form field is confusing, you can fix it in an afternoon. It’s like deciding to paint the living room blue instead of beige, or replacing the carpet with hardwood. The structure remains untouched, and the work is contained.
Key constructs in the project, like the domain model, can be modified with substantial effort. Imagine you need to move the main water heater, remove a non-bearing wall, or reroute the electrical panel because the building codes changed or your needs evolved. You can’t just paint over it; you have to shut down power, drain pipes, and carefully navigate around existing walls. In software, this is like changing how a “User” entity relates to an “Order” or splitting a service into two. It breaks existing integrations, requires data migration, and forces the whole team to pause while the “plumbing” is reworked.
How the software is decomposed is even harder to change. The decomposition shapes the system and changing it requires major effort. You are changing key support structures. Think of it as realizing halfway through construction that the staircase is in the wrong place, blocking the flow of the entire house. To fix it, you might have to tear down a load-bearing wall, install temporary supports, and rebuild the second floor. In software, this is the nightmare of trying to move from a monolith to microservices, or redefining your core business boundaries after years of development. It’s not just a refactor; it’s a reconstruction of how the teams and systems communicate. Extensions are far easier, like a new business module for software or a veranda for a house.2
Finally, the technologies that are used lay the foundation. Changing them may mean rewriting the whole system. This is the equivalent of deciding three years into a build that you want to switch from a concrete foundation to a timber frame. You can’t just patch it; you have to dig up the site and start from zero. In software, this is the decision to migrate from Java to Go, or from SQL to NoSQL. It often means the old system becomes obsolete, and the only path forward is a complete rewrite.3
I disliked the architecture metaphor because I had categorized too much work under it. Over the lifetime of a software system, architecture happens intensely at the beginning and then occasionally later on. Most of the work isn’t architecture work. It’s interior design and systems selection. People move in and out, swap furniture, and do light renovations. It requires taste and care and is valuable—but it isn’t architecture.
- This is similar to concept of “shearing layers” from Duffy and Brand. The layers in the table are a variation of their concept. ↩︎
- Over long period of time, buildings can still change significantly, as shown in the book “How Buildings Learn” from Brand. ↩︎
- Some pretty impressive can happen to buildings nevertheless, like rotating a building 90°! ↩︎
Shift-Left for Management
In IT, “shift-left” means integrating testing, quality checks, and feedback loops earlier in the software development lifecycle (SDLC). Instead of finding problems during final testing, when fixes are slow and expensive, teams identify and resolve them at the earliest possible stage.
Interestingly, the same idea can be transposed to management.
The management lifecycle consists of defining the mission, values, processes, and structures, and then conducting the work accordingly. It is a lifecycle because management must periodically inspect how the system performs and iterate the whole system to adjust to new realities.
Instead of fixing problems late in the lifecycle, we should try to address them in earlier stages. To prevent operational problems, improve processes and structures. To prevent processes issues, improve the mission and values. 1
Shift-left aims at fixing root causes, not symptoms. In IT, scaling issues often lead teams to add servers or optimize queries. But if the software design wasn’t built for scale, these are temporary fixes. The real solution is to fix the architecture. In management, cross-team performance issues often lead to more meetings, stricter coordination, or additional oversight. But if the team structure creates silos, no amount of coordination will help. The real solution is to reorganize teams to match workflows. In both cases, fighting operational limits treats the symptom. Fixing the underlying design addresses the cause. And the earlier you do this, the less it costs.
In IT, you can test changes on test systems before rolling them out. In organizations, this is harder. You have only one organization, and you cannot simply “roll back” a failed culture change. However, the patterns still apply. You can run A/B tests or “canary releases” by piloting new processes in a single team before a company-wide rollout. You can also improve quality through design reviews and retrospectives.
There are many workable parallels, because IT is about engineering systems, management is about engineering organizations. Both require designing for reliability, iterating based on feedback, and fixing root causes before they propagate.
- For instance, to prevent bugs in production, improve the testing process. To improve engagement in testing, anchor quality and testing as a value. ↩︎
AI and the Economics of Software Development
In his seminal essay “No Silver Bullet,” Brooks defined the concept of accidental versus essential complexity in software development. Essential complexity is the irreducible complexity of the problem you want to solve. Accidental complexity is the complexity introduced by implementation choices, which we aim to minimize.
Typing was never the bottleneck in software development, but managing accidental complexity is. There are good reasons to think AI can effectively address accidental complexity significantly.
However, to understand where AI can make the greatest impact, we must first examine where this accidental complexity originates. A major contributor is that, by default, we engineer systems using technologies designed for internet-scale applications. If your software is internet-scale, the complexity of modern frameworks is partly essential—scaling brings irreducible complexity with it. But if your system isn’t internet-scale, all this complexity is accidental. Instead of a simple PHP file, you now have an Angular application with a separate frontend and backend in a three-tiered architecture consisting of at least 20 files. You are expected to build your application cloud-native, even if you don’t really need the cloud.
There are many straightforward refactorings that teams don’t implement because they are too expensive. Think of changing the name of a domain attribute in your model. It can easily ripple through many artifacts—from domain models to unit tests to database schemas. Basically, many cross-cutting changes are usually not carried out because they have poor economics. Over time, the consequence is design erosion.
AI excels at these changes, executing ripple effects across the codebase without the cost or fatigue that currently deter human developers. More broadly, anything that qualifies as “boilerplate code” is accidental complexity and can be handled by AI. This significantly changes the economics of software maintenance and development.
Related
- This post has been inspired by https://ian-cooper.writeas.com/is-ai-a-silver-bullet
- https://haskellforall.com/2026/03/a-sufficiently-detailed-spec-is-code – I think the argument here is missing the distinction between essential and accidental complexity
Will AI Kill Agile Software Development?
Will AI kill agile software development? Looking at Atlassian’s recent plunge suggests investors think the usual agile setup—JIRA, stories, sprint boards—could face a big disruption. That makes many wonder if the old way of working with stories and features will disappear.
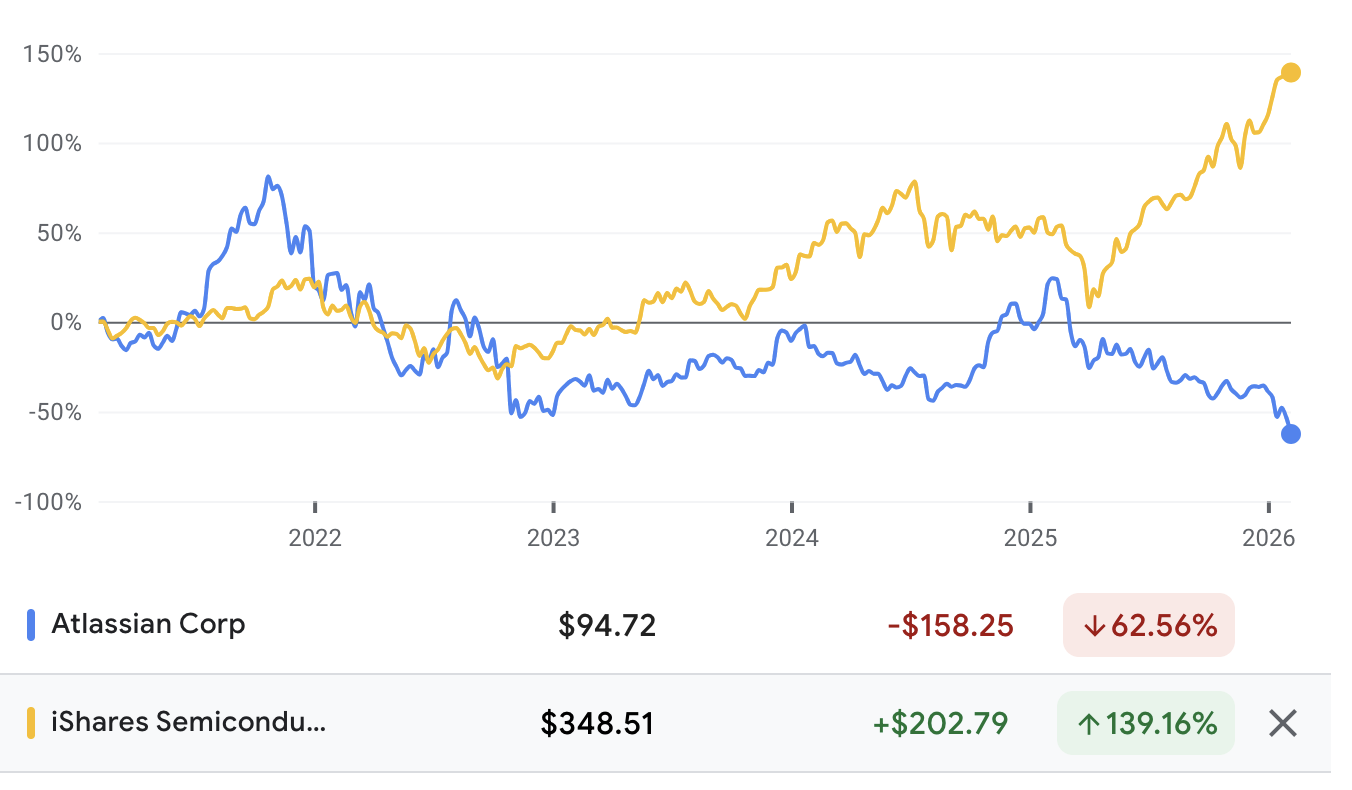
At its core, agile is about evolving requirements iteratively. Stories and features aren’t the real requirements, they’re just a way for people to organise work. Even if machines write the code, we still need a clear set of goals. Those goals will still exist, but they might live somewhere else.
One option is to keep requirements inside the codebase itself, either as additional artifact or in the form of tests. Big or regulated projects will still need dedicated requirement‑management tools (for example, Polarion) to keep versions, approvals and audit trails. Those tools will keep feeding AI the context it needs while providing the governance many companies require.
AI can actually help the agile process. A product owner can give a high‑level feature description to an AI, and the AI can break it into small implementation steps (stories), write acceptance criteria and draft a first version of the code. The backlog stays, but the heavy lifting of splitting work is done by the machine, possibly asking for clarification interactively.
Whether the implementation steps will be persisted if the AI does the work and not a human will depend on our needs of observability. Since it doesn’t cost much to persist the implementation steps, I guess we will keep storing them to track progress and flag problems.
The three main parts of software delivery—requirement management, work organisation and development environments—will still be separate, but AI will tie them together more tightly. Requirement‑management platforms will keep governance, work‑organisation tools will continue to help teams prioritise and visualise work, and IDEs such as IntelliJ will still provide debugging, testing and refactoring, now with extra AI‑generated code suggestions.
Overall, AI is unlikely to kill agile — at least not yet. Instead, it will change where requirements live, how stories are created and how tools interact with each other.
Thinking and Retrieval in the AI Stack
The modern AI stack can be viewed as three logical layers: Compute, Model, and Agent. While thinking (reasoning) and retrieval (fetching external information) may span multiple layers, separating them helps us reason about trade‑offs such as latency, observability, and cost.
| Layer | Primary Function | Typical Primitive |
|---|---|---|
| Compute | Executes the heavy‑weight operations that power the stack. | GPU/TPU kernels for transformer forward passes; ANN‑search kernels; CPU‑based HTTP calls to external services. |
| Model | Performs core reasoning and, optionally, internal retrieval. | • Native chain‑of‑thought – the model generates step‑by‑step reasoning within a single forward pass (e.g., “Let’s think step‑by‑step…”). • Built‑in retriever – the model invokes a search tool (e.g., GPT‑4o browsing, Claude “search”, Gemini grounding) and conditions its output on the returned snippets. |
| Agent | Orchestrates complex workflows, decides when to call the model, and handles external data sources. | • Agent‑orchestrated reasoning – the agent decomposes a problem, builds prompts, may run meta‑reasoning loops, and determines when to invoke the model again. • External retrieval – the agent queries a vector store, a web‑search API, or any custom data source, then injects the retrieved passages into the next model prompt. |
Whether thinking or retrieval happens in Model vs. Agent has some implications.
| Dimension | Thinking – Model | Thinking – Agent | Retrieval – Model | Retrieval – Agent |
|---|---|---|---|---|
| Latency | One forward pass → minimal overhead (unless the model also does internal search). | Multiple orchestrated calls → higher latency, but sub‑tasks can run in parallel. | Single endpoint (e.g., POST /v1/chat/completions with built‑in tool) → low latency. | Two‑step flow (search → prompt → model) → added round‑trip time, but can parallelise search with other work. |
| Control / Policy | Model decides autonomously when to fetch external data → harder to audit or enforce policies. | Agent mediates every external call → straightforward throttling, redaction, logging, and policy enforcement. | Retrieval baked into the model → policy changes require a new model version. | Agent can enforce dynamic policies (rate limits, content filters) on each external request. |
| Resource Use | GPU must handle both inference and any ANN‑search kernels; higher compute density. | Retrieval can be off‑loaded to cheaper CPUs or dedicated search services; GPU used mainly for inference. | GPU handles only inference; no extra search kernels needed. | CPU or specialised search services handle retrieval, freeing GPU capacity for inference. |
| Observability | Reasoning is embedded in the token stream → debugging is indirect; limited visibility. | Agent logs each sub‑task, providing a clear, structured trace of why and when calls were made. | Limited visibility beyond token usage; retrieval is opaque to the caller. | Agent records search queries, responses, and any filtering applied, giving end‑to‑end traceability. |
If you are building an agentic system, you’ll need to decide which responsibilities belong to the model and which to the agent.
If you are merely a user of such a system, the distinction is mostly invisible, showing up only as differences in answer quality, latency, and cost.
Is Spec-Driven Development the Future?
In Climbing the Abstraction Ladder with LLMs, I shared some early thoughts on how large language models might push software development toward a more spec-driven approach. With the rise of agentic AI, this shift is no longer theoretical. We are starting to see it take shape in practice, often under the label spec-driven development (SDD).
If we think of SDD as a new paradigm—on par with object-oriented or functional programming—we can look at the past to try to anticipate the future. New tools and platforms will emerge that are designed specifically for this way of working, much like Smalltalk or Lisp were for earlier paradigms. Early adopters will build real systems with them, and some of those systems will look very impressive.
What will take much longer is understanding how well SDD holds up over the entire software lifecycle. The long-term impact of a paradigm, especially on maintainability and evolution, is hard to judge early on. Organizations can reasonably try SDD on non-critical projects, but for critical systems the risks are still significant. Too many questions remain unanswered.
History also suggests some caution. If OOP and FP are any indication, a new paradigm rarely succeeds in its pure form. What we call OOP today is a pragmatic version that still contains a lot of procedural code. Functional programming entered the mainstream in an even weaker form—immutability and lambdas, but rarely full-blown higher-order functional design. SDD will likely follow the same path. The version that survives in industry probably won’t be fully spec-driven.
As usual, non-functional requirements are where things get complicated. New paradigms tend to work well for simple cases, but persistence made OOP messy, and performance constraints often make FP hard to apply in practice. There is no reason to expect SDD to be different. Once non-functional requirements dominate, architectural decisions become central—and that’s where abstractions start to leak.
It is worth considering some critiques of this view. First, SDD may not be a full paradigm but rather a technique layered on top of existing paradigms, in which case expecting a long evolution from “pure” to pragmatic may be misleading. Second, non-functional requirements might be incorporated into the specs themselves, changing the traditional failure points. Finally, architecture might become more of a search or simulation problem for agents, rather than a human-only domain, which could make SDD more effective than expected. These critiques suggest that SDD’s trajectory could be very different from past paradigms, and that its eventual form may be more disruptive than a cautious hybrid would imply.
Assuming these critiques don’t hold, SDD should not be seen as a replacement for software design, but as a new abstraction that shifts where effort is spent. Over time, the industry will likely settle on a hybrid approach: partly spec-driven, partly traditional, and pragmatic above all. As with earlier paradigm shifts, success will come from understanding both the power and the limits of the abstraction.
Alternatives to US Tech Exist
Since the beginning of the new Trump administration, anxiety about U.S. tech dominance has been on the rise. Over the past few decades Europe’s position as a technology leader has slipped, and most of the continent’s biggest corporations now operate outside the core tech arena. Today the two unmistakable European tech giants are ASML and SAP. The internet revolution was largely handed over to American firms, with perhaps the lone notable exception of Spotify. Even though talent is abundant across Europe, many promising entrepreneurs choose to relocate to the United States. Still, a number of home‑grown companies are showing real promise; examples include Mistral, a cutting‑edge AI startup, and OV Cloud, a cloud‑infrastructure provider. If Europe wants to stay relevant on the global stage, it must rebuild a vibrant technology ecosystem.
One practical way we can contribute is by adopting local alternatives whenever possible. Switching costs for many services are surprisingly low—for instance, moving away from the Google Workspace suite can be done with little effort (except maybe for the email address). Proton.me is a compelling alternative. I plan to transition all of my non‑email workflows to Proton’s suite, and if the experience proves solid I’ll eventually move my email there as well. There’s much to like about Proton: The company was founded by scientists, which gives it a research‑driven, privacy‑first mindset. Its security‑focused architecture protects data from the ground up. Strong branding adds to its appeal. The name “Proton” is well chosen, and the Lumo mascot (the cat) whimsically recalls the vibe of games like Monument Valley.
A sizable portion of Europe’s tech talent already works for U.S. firms that have European offices—think Google in Zürich or Microsoft in Dublin. If a truly competitive European tech sector emerges, offering salaries and growth prospects on par with Silicon Valley, those professionals could switch quickly. The bottleneck isn’t a lack of talent; it’s the absence of European companies that appeal to this talent. That could change dramatically once the sector gains momentum.
Europe still possesses the expertise, the research institutions, and the entrepreneurial spirit needed to compete globally. Europe has a fragmented market and more regulations than the US, which is a structural disadvantage. However, a new structural advantage may be emerging: greater predictability and stability.
There may also be an opportunity to rethink services and product for AI. Doing this on existing mature products may be harder than on new products. The ideal outcome of a European Tech Renaissance would be new, AI‑first products built from the ground up.
Don’t Jump to the Solution
We have all been faced with someone jumping to conclusions. Less obvious, but just as common, is jumping to solutions.
You jump to conclusions when you overlook facts and alternative explanations. You jump to solutions when you overlook the problem itself and the many ways it could be approached. Both come from the same impulse to move fast and feel done.
Jumping to a solution can be costly. There is the obvious opportunity cost. Are you solving the most valuable problem? Is there even a real problem there? On top of that, the solution you rushed into might be the wrong one, or a decent one that crowds out a much better option you never explored.
You also miss a lot of the fun. Exploring the problem space is often the most interesting part of the work. That is where insights appear and where you actually learn something. If you jump too fast, you skip that phase entirely and turn the work into execution only.
Finally, you risk losing buy in. When you arrive with a fully formed solution, especially if you did it alone, people rarely feel ownership. At best they disengage. At worst they push back. Most people want a voice in how problems are framed and solved.
This is a lesson I keep relearning. Bring problems, not solutions.
Go Chronological
For many years I tried to come up with a clever system to organize my digital life.
I explored systems with folder structures, categories, labels, and nomenclature. Now, I’m convinced that the simplest and most effective approach is also the least ambitious one. Go chronological.
Forget about building complex structures that should work now and in ten years. Just store everything by year. Inside each year, create a handful of buckets using whatever grouping makes sense at the time. Taxes, pictures, projects, information, things that matter at the moment. Usually you end up with five to twenty buckets.
Life changes, and this approach deals with that naturally. You do not need a future proof system. Each year stands on its own and can use its own categories. Time provides the only stable axis.
At first, retrieval sounds inefficient. In practice it works surprisingly well. Most of the time you know the year. Once you have that, finding the right bucket is either straightforward or a matter of a few clicks. Within one year, misclassification isn’t an issue. Even if you need to check a couple of nearby years and the buckets look slightly different, it is still no big deal. The approach trades classification purity with simplicity.
Searching across many years can be less convenient, but this happens rarely. And when it does, full text search exists.
Archiving is trivial. A year is done, you close it, and you move on.
Truly long lasting projects can live outside of this structure, but they should be the exception. Recurring administrative topics do not qualify.
There is also something quietly profound in all of this. Even in a long career, you will likely end up with sixty to eighty yearly folders. That is a small enough number to manage without much effort. Your life is actually short.
With 2026 around the corner, it is time to create a new folder and start bucketing again.
